
Closing the Observability Gap in Enterprise AI
Recent real-world AI incidents have shown that AI systems can fail while everything appears operational – especially in on-premise, hybrid, and sovereign AI environments.
Organizations are already facing situations where AI assistants generate hallucinated responses, expose unsafe content, violate policy controls, or produce misleading outputs – without any obvious infrastructure outage or application failure.
More concerning is that traditional monitoring tools often continue to report healthy systems while business outcomes quietly degrade.
As enterprises move generative AI and agentic AI workloads from experimentation into production, these new operational risks are increasingly creating an observability gap that traditional monitoring approaches were never designed to address.
The challenge
AI systems introduce failure modes that are fundamentally different from traditional applications:
- Hallucinations – generating plausible but incorrect information
- Policy violations – producing content that breaks safety or compliance rules
- Misleading outputs – responses that appear correct but are actually wrong
- Cost drift – token usage spiraling without visibility
Traditional monitoring tools track infrastructure metrics – CPU, memory, network, uptime. They don’t track whether an AI’s response is accurate, safe, or appropriate. That’s the observability gap.
A practical solution
An observability solution has been developed to address these challenges, enabling AI to be deployed with confidence on enterprise AI infrastructure.
The approach combines:
- Infrastructure observability – tracking system health and performance
- AI agent monitoring – tracking what AI systems are actually doing
- Governance controls – ensuring compliance and policy adherence
- Operational workflows – integrating observability into daily operations
Key capabilities include:
- Detect quality, safety, reliability, and cost issues across AI systems in real time
- Monitor AI infrastructure, agents, and workflows end-to-end
- Correlate infrastructure telemetry with AI behavior and business outcomes
- Maintain governance and compliance for sensitive AI interaction data
- Support secure on-premise, hybrid, and sovereign AI deployment models
- Reduce AI system risk at scale and improve operational efficiency
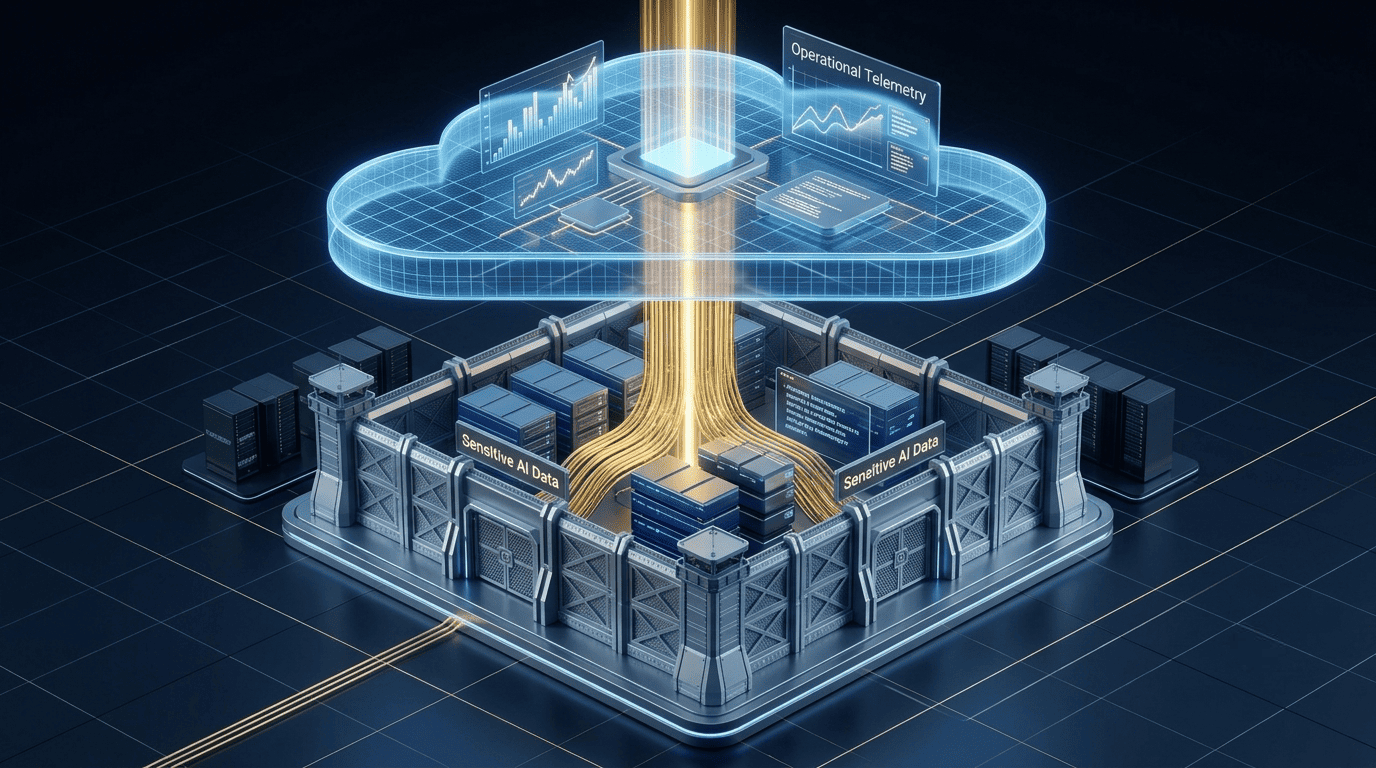
The split-plane observability architecture
A key architectural innovation is the split-plane approach:
Operational telemetry (infrastructure metrics, performance data) is analyzed in a cloud-based observability platform.
Sensitive AI interaction data (prompts, responses, audit records, governed data) remains securely managed in an enterprise data platform.
This split ensures that sensitive data stays protected while still enabling comprehensive monitoring and troubleshooting.
AI-specific observability domains
The solution addresses observability areas that are unique to AI systems:
- Hallucination detection – identifying when AI generates incorrect or fabricated information
- Quality evaluation – measuring response quality against benchmarks
- Token and cost monitoring – tracking usage and preventing cost overruns
- Guardrail visibility – monitoring whether safety and policy controls are working
- Troubleshooting workflows – making it easier to diagnose and fix issues
- Governance controls – ensuring compliance with internal and regulatory requirements
Why this matters
For organizations moving AI from experimentation into production, observability is rapidly becoming as important as the models themselves.
Without proper observability, organizations face:
- Unpredictable AI behavior that can’t be explained or traced
- Compliance and regulatory risks from undocumented AI decisions
- Cost overruns from uncontrolled token usage
- Reputational damage from public AI failures
With proper observability, organizations can:
- Deploy AI with confidence, knowing issues can be detected and resolved
- Maintain trust with users and regulators
- Optimize costs and performance continuously
- Learn from failures and improve systems over time
The bottom line
AI systems are fundamentally different from traditional software. They require a new approach to monitoring and observability.
Traditional infrastructure monitoring tells you if the system is running. Observability tells you if the system is working correctly, safely, and efficiently.
As enterprises scale AI from pilots to production, closing the observability gap isn’t optional – it’s essential.
HexPulse
June 20, 2026The key insight here is that AI failures are silent – traditional monitoring shows “everything is green” while the AI is hallucinating or breaking policies. A whole new observability layer is needed.
StackForge
June 21, 2026The split-plane architecture is smart – operational metrics can go to standard observability tools, but sensitive prompts and responses need to stay in a secure environment. That’s a practical governance solution.
BitCatalyst
June 26, 2026Hallucination detection and cost monitoring are two sides of the same coin. Without both, enterprises can’t scale AI – they’ll either lose trust (hallucinations) or lose money (uncontrolled token usage).