
What Do AI Observability Tools Actually Do? (And Why They’re Not Enough)
Key Takeaways
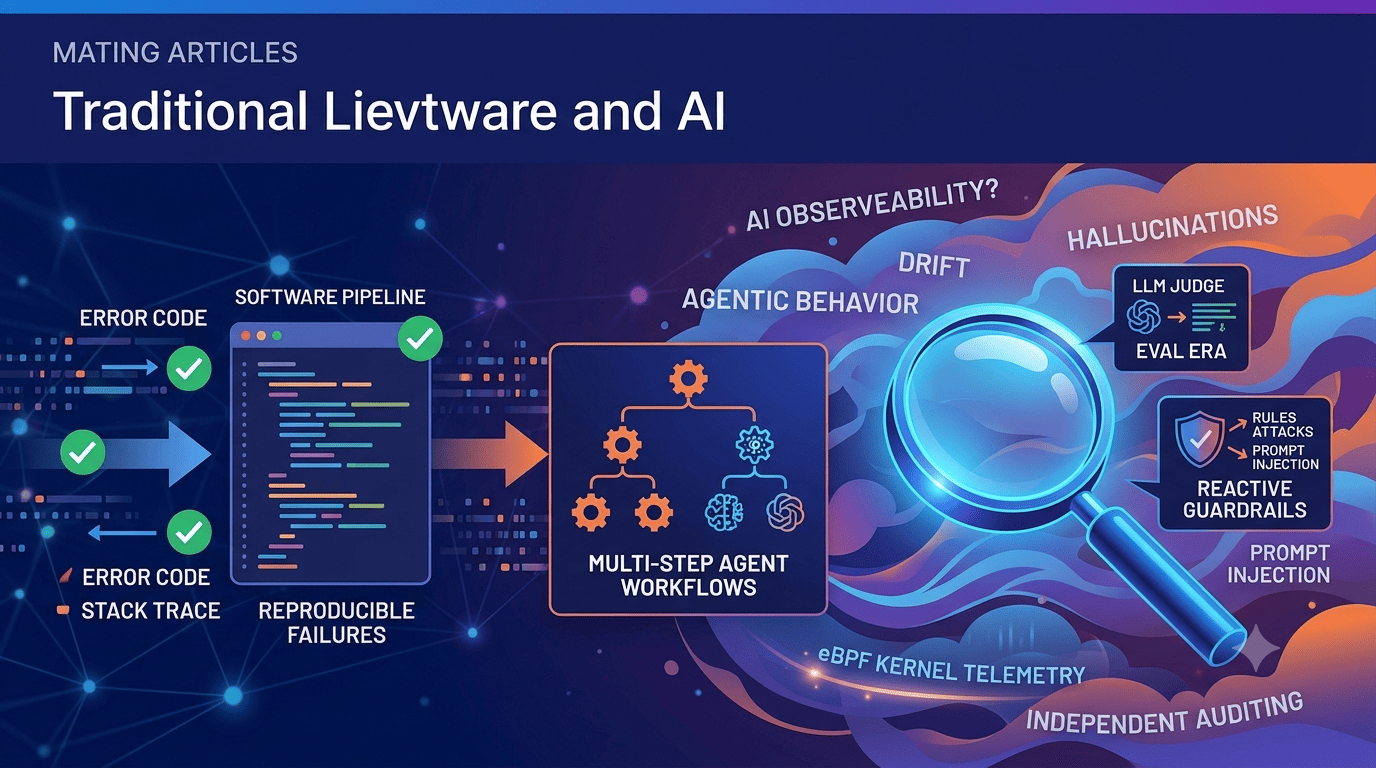
- AI systems fail differently than traditional software—no clean error codes, no predictable paths. They drift, hallucinate, and degrade in subtle, intermittent, and nearly impossible‑to‑reproduce ways.
- Today’s AI observability is stuck in the “eval” era: scoring outputs after the fact with test sets, human judges, or LLM‑as‑a‑judge. This is static, offline, and backward‑looking—it tells you how a model did on known inputs, not how it’s doing right now with unpredictable production traffic.
- Security has become a major driver, with guardrails trying to catch prompt injections, PII leaks, and jailbreaks—but these are reactive and rule‑based, while attacks evolve faster than rules can keep up.
- The next big wave is agentic AI—systems that make decisions, orchestrate multiple models, use tools, and run multi‑step workflows. They need observability that captures decision paths, tool usage, and behaviour over time, not just single inference calls.
- Kernel‑level approaches like eBPF are emerging as a critical layer for independent, tamper‑proof telemetry—because if an AI agent reports its own behaviour, who’s auditing the auditor?
The Trust Gap in AI Observability
When your software crashes, you get a stack trace. When a database query times out, you get an error code. These failures are deterministic—you can reproduce them, fix them, and move on.
AI doesn’t work that way. It drifts. It hallucinates. It can be perfectly fine for 999 requests and then, on the thousandth, produce something bizarre or even dangerous. And when it does, there’s no error log that says “Hallucination occurred due to context drift.”
The tools we’ve built to monitor traditional apps don’t map cleanly onto this new reality. So teams are scrambling to adapt, but many are realising that today’s AI observability solutions are, at their core, built for yesterday’s problems.
The Eval‑Centric World
Walk into any AI team today and you’ll hear one word more than any other: evals.
Most tools are built around evaluating model outputs after the fact. You throw a test dataset at the model, you have human raters or an LLM judge score the answers, and you get a number that tells you how good your model is—or at least how good it was on that particular set of questions.
Evals are useful. They help you compare versions, catch regressions, and benchmark progress. But they share a critical blind spot: they’re backward‑looking.
They tell you how the model performed on a predefined set of inputs—not what’s happening in production, where inputs are messy, context shifts, and users ask unexpected questions. They also don’t capture multi‑step workflows, tool‑calling sequences, or the behaviour of systems composed of multiple models and APIs.
Even when you add human feedback, it’s expensive, inconsistent, and slow. Domain experts are hard to come by, and it’s often unclear whether a failure came from missing context, a bad RAG implementation, the model itself, or feedback poisoning.
Some progress is coming from OpenTelemetry and LLM tracing—they’re early attempts to bring runtime visibility into AI systems. But they’re still just first steps. The core problem remains: you can’t understand AI by evaluating it after the fact. You need to watch it while it’s running.
The Security Panic: Guardrails, PII, and Prompt Injection
As AI systems move into production, observability is rapidly becoming a security concern. The attack surface is massive:
- Prompt injection attacks (tricking the model into ignoring its instructions)
- Jailbreaks (bypassing safety filters)
- Leakage of sensitive data, including personally identifiable information (PII)
- Unexpected behaviour triggered by malicious edge cases
Enter the guardrail industry. These tools monitor inputs and outputs in real time, flagging or blocking unsafe content. They act as a safety net between users and models.
In theory, that’s great. In practice, most guardrails are reactive and rule‑based. They rely on classifiers or keyword filters that try to catch known bad patterns. But adversarial inputs evolve fast, and what works today might be obsolete tomorrow.
There’s a deeper problem, too: guardrails assume you already have decent visibility into the system. But many teams lack the basic telemetry to understand how and why a failure occurred in the first place. You can’t block what you can’t see.
This creates a gap between what guardrails promise (real‑time protection) and what they can actually deliver. Closing that gap requires rethinking observability from the ground up—not just filtering inputs and outputs.
The Agentic Future: Observability for Decision‑Makers
The next phase of AI is all about autonomous agents. Instead of single inference calls, we’ll have systems that:
- Orchestrate multiple models
- Call external tools and APIs
- Execute complex, multi‑step workflows over minutes or hours
- Make decisions, not just generate text
These are fundamentally different from the models we’ve been monitoring so far. And they demand a different kind of observability.
Just as containers needed Kubernetes to become manageable at scale, AI agents will need their own orchestration and control layer. That layer must capture:
- Decision paths (why did the agent choose that tool?)
- Tool usage (what did it call, and with what parameters?)
- Resource consumption (time, tokens, cost)
- Interactions between agents
- Behaviour over time, not just snapshots
In many ways, this mirrors the evolution of cloud‑native observability. We moved from simple metrics to logs, metrics, and traces—a three‑pillar approach—to understand distributed systems. Now we need the equivalent for agentic systems.
And as AI becomes embedded across the entire software lifecycle—from code generation to testing to operations—observability transforms into a system of truth that feeds both humans and machines. AI agents can only build, debug, and improve systems if they have rich, high‑fidelity context. Observability is what provides that context.
Why Kernel‑Space Observability Is the Next Frontier
There’s a fundamental trust problem at the heart of AI observability. If an AI agent is responsible for reporting its own behaviour—logging its own decisions, instrumenting its own code—how do you know that report is accurate?
Traditional observability relies heavily on application‑layer instrumentation. But instrumentation can be incomplete, misconfigured, or simply bypassed. And as AI agents start writing their own code, they won’t think like human engineers when it comes to adding telemetry—nor should they be expected to.
That’s where kernel‑level approaches, especially eBPF, become critical. By operating at the kernel level, eBPF can:
- Capture system behaviour without modifying application code
- Eliminate blind spots caused by missing or broken instrumentation
- Provide consistent visibility across all workloads—whether human‑written or AI‑generated
Most importantly, eBPF gives you an independent, trusted source of truth. In high‑stakes environments where compliance, security, and reliability are non‑negotiable, you need telemetry that’s not influenced by the systems it observes.
Three Things the Next Generation of AI Observability Must Do
If today’s tools are falling short, what should we be building instead?
1. Behavioral Anomaly Detection
Traditional observability looks at latency, errors, and resource usage. AI systems need a different lens: detecting when behaviour deviates from expectations, even when no explicit “error” is thrown. That means learning what “normal” looks like and spotting drift, not just crashes.
2. Tamper‑Proof Audit Trails
As AI takes on more responsibility, we must be able to reconstruct decisions—not just what happened, but why. And we need to trust that the data hasn’t been altered. Cryptographic integrity and independent verification become essential.
3. Dynamic and Adaptive Observability
Static dashboards and fixed metrics won’t work in an environment that changes constantly. Observability must adjust data collection in real time—increasing granularity during incidents, focusing on what matters in the moment, and feeding that intelligence back into the system.
Finally, observability must become a first‑class citizen of AI workflows. It’s no longer enough to surface insights to human operators. The same telemetry must be consumable by AI agents themselves, enabling them to debug, optimize, and improve autonomously.
Observability as Infrastructure, Not an Afterthought
We’re still early in the journey. Most of today’s AI observability tools are existing paradigms stretched and patched to fit new problems. They solve pieces, but not the whole.
The next generation will look very different. Observability will become a foundational layer—enabling AI systems to operate safely, efficiently, and autonomously. The teams that recognise this shift early will have a huge advantage.
In a world of non‑deterministic systems, long‑running agents, and ever‑evolving threats, one truth becomes clear: your AI is only as reliable as your ability to observe it.